Come Trovare File Duplicati in Linux

Trovare file duplicati in un sistema Linux è un’operazione comune che può aiutare a liberare spazio su disco e mantenere il sistema organizzato. In questo articolo, esploreremo questi metodi in dettaglio.
Metodi per Trovare File Duplicati
Utilizzo di fdupes
fdupes è uno strumento specificamente progettato per trovare file duplicati in directory.
Installazione:
sudo apt-get install fdupes # Debian/Ubuntu
sudo dnf install fdupes # Fedora/RHELUtilizzo base:
fdupes -r /path/to/directoryL’opzione -r cerca ricorsivamente nelle sottodirectory.
Con find e md5sum
Una combinazione di find e md5sum può essere usata per identificare duplicati:
find /path/to/directory -type f -exec md5sum {} + | sort | uniq -w32 -dDQuesto comando:
Trova tutti i file nella directory
Calcola l’hash MD5 per ciascuno
Ordina i risultati
Mostra solo i duplicati
Utilizzando rdfind
rdfind è un altro strumento efficace che può anche rimuovere automaticamente i duplicati.
Installazione:
sudo apt-get install rdfind # Debian/Ubuntu
sudo dnf install rdfind # Fedora/RHELUtilizzo:
rdfind /path/to/directory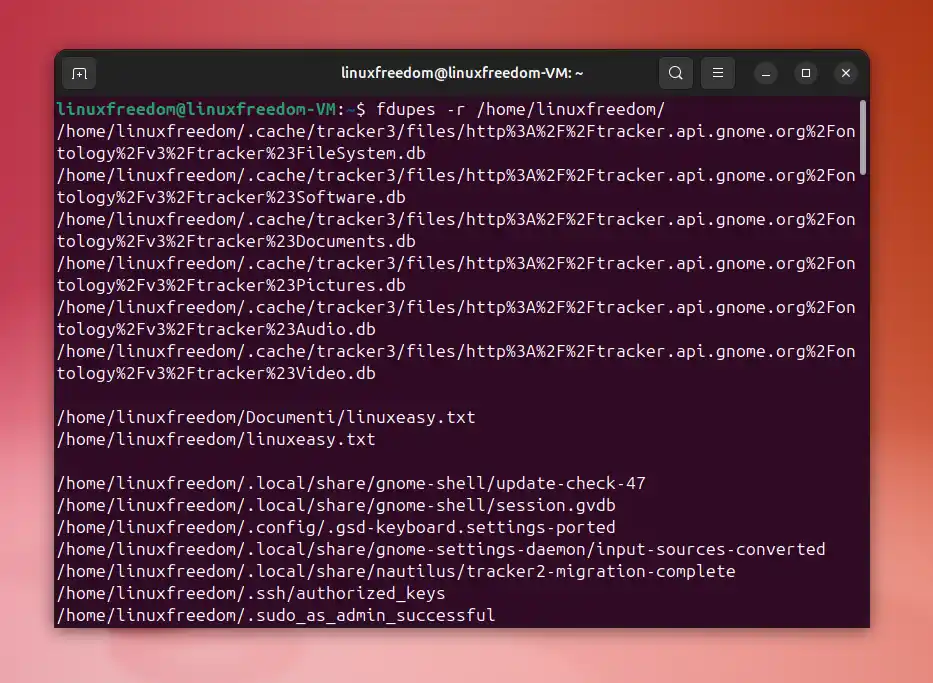
Confronto tra i Metodi
| Strumento | Velocità | Funzionalità | Faciltà d’uso |
|---|---|---|---|
| fdupes | Media | Buona | Alta |
| find+md5sum | Lenta | Base | Media |
| rdfind | Veloce | Avanzata | Alta |
Consigli per la Gestione dei Duplicati
Backup prima di eliminare: Sempre fare backup prima di rimuovere file
Verifica i risultati: Controlla manualmente i file prima di eliminarli
Script automatici: Per sistemi grandi, considera l’automazione con script
Trovare file duplicati in Linux è semplice con gli strumenti giusti. fdupes offre un buon equilibrio tra funzionalità e facilità d’uso, mentre rdfind è eccellente per operazioni più avanzate. Per soluzioni temporanee, la combinazione find+md5sum è sempre disponibile.